La condivisione dei risultati di digitalizzazione e trascrizione dell'archivio ha posto successivamente il problema dell'adozione di uno standard che permetta una diffusione dei testi sul web in un formato leggibile da ogni sistema informatico esistente (in letteratura: machine readable form). E' questo un quesito chiave di quel ramo dell'informatica denominato “informatica umanistica” che propone l'applicazione delle tecnologie elettroniche alla gestione dei dati testuali e delle fonti, a oggi essenzialmente disponibili su supporto cartaceo.
L'iniziativa TEI (Text Encoding Iniziative) è un progetto internazionale, attivo dal 1987 e promosso attualmente dalle tre maggiori associazioni mondiali di studiosi di scienze umane attraverso metodologie informatiche, la Association for Computers and the Humanities (ACH) la Association for Computational Linguistics (ACL) e la Association for Literary and Linguistic Computing (ALLC). Lo schema TEI è il risultato finale degli sforzi ventennali di definizione di uno standard internazionale che garantisce la validità scientifica della codifica, l’intercambiabilità e la portabilità dei testi in formato elettronico. TEI si occupa della creazione di un formato comune per la codifica di testi letterari in formato digitale attraverso l'utilizzo del linguaggio XML (eXtensible Markup Language), universalmente riconosciuto, grazie alla sua flessibilità ed estendibilità, come il miglior sistema per creare e descrivere basi di dati. L'obiettivo principale di TEI è la compatibilità dei testi codificati secondo questo standard e il progetto ha rilasciato negli anni differenti versioni, caratterizzate da modelli sempre più sofisticati e finalizzati alla trascrizione di corpora appartenenti a diverse discipline (teatro, prosa, poesia, dialoghi ecc.). La versione attualmente in uso, la TEI P5 prevede l'utilizzo di un nucleo comune a tutti i documenti TEI (TEI core) e moduli specifici per tipologie di testi, come il TEI for manuscripts, che prevede una serie di tag (marcatori) specifici per la descrizione del manoscritto antico.
La scelta del modello TEI per la codifica elettronica dei testi permette di beneficiare dell'esperienza accumulata dall'azienda capofila del progetto finanziato dalla Regione Toscana, Tiphys S.r.l., nel campo dei linguaggi di programmazione per il web, nonché dell’apporto scientifico di Marco Marcellini, docente di “linguaggi di marcatura dei testi” presso l'Università di Siena, Facoltà di Lettere e Filosofa di Arezzo, fino al 2010 e del confronto con le metodologie adottate da centri di ricerca nazionali e internazionali, grazie all’organizzazione e alla partecipazione a Seminari e Tavole rotonde specifiche.
Nell'elaborare il modello di marcatura dei documenti specifico per il progetto Re.Me.Dia., il gruppo di ricerca ha ritenuto utile confrontare le proprie esperienze in tema di linguaggio XML e applicazione di TEI ai documenti antichi, con quelle di progetti già avviati in Italia e all'estero da parte di importanti istituzioni culturali internazionali.
L'occasione si è presentata nel mese di dicembre 2010 in occasione del seminario tenuto a Siena (collegio Santa Chiara), per la scuola di dottorato in “Scienze del Testo”, dal prof. Michele Ansani dell'Università di Pavia. Il docente, principale autore del “Codice Diplomatico Lombardia Medievale” (http://cdlm.unipv.it/ ) ha tenuto un ciclo di lezioni con il seguente calendario:
L'altro progetto con cui si è aperto un confronto prima dell'elaborazione dello specifico modello XML per la marcatura del Codice Diplomatico Aretino è quello redatto dall'École Nationale des Chartes con sede a Parigi, ente universitario che è parte, assieme al King's College di Londra e al già citato Centro Interdipartimentale di Studi sui Beni Librari e Archivistici dell’Università di Siena di un gruppo di lavoro internazionale per l'edizione digitale dei documenti.
Entrambe le istituzioni ora citate hanno “pubblicato” sul web un loro codice diplomatico digitale. In nessun caso però, i documenti digitali xml sono stati prodotti mediante uno specifico software (si è utilizzato un editor standard), né vi è collegamento o inclusione nel database della foto-riproduzione della pergamena o del manoscritto originale; inoltre il Codice Diplomatico Lombardo non si avvale dello schema TEI, di fatto rendendo i documenti prodotti non confrontabili con altri in quanto non aderenti ad uno standard riconosciuto.
L'occasione di confronto con il prof. Ansani e con quello che si può definire “modello francese” sviluppato secondo TEI-P5 ha consentito, però, di “mettere sul tavolo” i dubbi relativi all'adozione di questo o quel tag (es. adozione di <DIV> piuttosto che <P2>) e di verificare sul campo la bontà dell'infrastruttura software progettata per il Codice Diplomatico Aretino, specie per quanto riguarda le funzionalità di affiancamento dell'immagine digitale al testo. Si ricorda che 2 DIV e P sono utilizzati dal modello TEI-P5 come marcatori per la suddivisione del testo.
Trascrivere un testo secondo il modello TEI significa andare oltre la sequenza di parole strettamente appartenenti al testo da trattare, sia esso la lista della spesa o una pagina della Commedia dantesca. Così come note a piè di pagina, titoli e sottotitoli costituiscono un necessario complemento alla comprensione di un testo letterario, anche le informazioni contenuto in un documento ogni testo codificato conformemente alle specifiche della TEI è costituito da due parti:
L’elemento text si divide, a sua volta, in quattro elementi:
Lo schema sottostante sintetizza la composizione di un testo codifcato secondo TEI:
Basando il modello di codifca su TEI P5 for manuscript1, set di marcatori TEI comprensivo del TEI CORE (nucleo comune a tutti i documenti TEI) e di specifici tags per la descrizione del manoscritto e delle fonti documentarie, così potrebbe apparire l'inizio del fle XML corrispondente ad un primo esperimento di codifica.
xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader type="ISBD-ER">
<fileDesc>
<titleStmt>
<title type="main">Codice Diplomatico Aretino</title>
<author>Marta Calleri</author>
<funder>Universita di Siena</funder>
</titleStmt>
<editionStmt>
<edition>Versione 0.9b</edition>
</editionStmt>
La descrizione di questo specifico set di tag è online all'uri http://www.tei-c.org/Guidelines/Customization/
<extent>
<seg type="designation">Codice Diplomatico Aretino</seg>
<seg type="size">21 files : 3 megabytes dimensione
provvisoria</seg>
</extent>
<publicationStmt>
<authority>Progetto Re.Me.Dia.<date>2010-06-08</date></authority>
<distributor>
<orgName type="UNISI">Universita di Siena</orgName>
<placeName>Sede di Arezzo</placeName>
<address>
<orgName type="CISLAB">C.I.S.L.A.B. - Centro
Interdipartimentale di Studi sui Beni Librari e Archivistici</orgName>
<orgName type="LETTEREAREZZO">Facolta di lettere e Filosofia
di Arezzo</orgName>
<addrLine>Viale Cittadini 33</addrLine>
<addrLine>Arezzo</addrLine>
<addrLine>52100</addrLine>
</address>
<email>info@remedialab.it</email>
</distributor>
<idno type="UNISI">0011</idno>
<availability n="0001s" status="free" rend="visible">
<p>Freely available, is a sample</p>
</availability>
<date>2010-06-08</date>
</publicationStmt>
<notesStmt>
<note>Documento di prova, test n.01</note>
<note>Canonica 1</note>
<note type="summary">Sigizo del fu Petrone vende al presbitero Leone del fu Domenico la metà di un appezzamento di terra con casa e vigna situato nella pieve di San Pietro in Agello, in casale Paterno, in località Givestelle, al prezzo di 20 soldi.</note>
… …
</TEI>
Il documento complessivo, corrispondente alla trascrizione della pergamena dell’Archivio Capitolare di Arezzo con segnatura “Canonica 1”, sarà un fle .XML di circa un migliaio di righe in linea con le direttive TEI P5.
CARATTERISTICHE DEL SOFTWARE
Il passaggio dalla semplice trascrizione del documento, realizzata con programmi di videoscrittura come Microsoft Word, all'edizione digitale ovvero al fle XML costruito rispettando le regole TEI è processo diffcile e suscettibile di numerosi errori.
Esistono in commercio software come Oxygen (www.oxygenxml.com), che nascono come editor xml generici e quindi pensati per programmatori o sistemisti piuttosto che per studiosi di documenti antichi. Il loro utilizzo richiede conoscenze informatiche avanzate e manca del tutto il collegamento visivo con la fotografa digitale del documento da marcare.
L'idea di base è stata quindi quella di realizzare un software di ausilio alla trascrizione e marcatura delle pergamene, dotato delle seguenti caratteristiche:
- aumento della facilità d'uso
- collegamento con le immagini delle pergamene, con funzionalità di zoom
- interfaccia con meno funzioni ma adatta ad utenti estranei alla struttura tipica di un software usato da programmatori e tecnici
- automazione di quante più funzioni possibile. Marcando documenti dello stesso tipo (medesima epoca, luogo, fondo, lingua) deve essere possibile impostare una sola volta le informazioni di base sulle caratteristiche. In pratica, il blocco TEI HEADER deve essere gestito in automatico dal software
- anche se deve essere garantita l'esportazione in formato XML TEI, i dati del singolo documento vengono memorizzati PRIMA in un database MySQL, per poter disporre con maggior facilità di indici e ricerche. Alternativamente, i soli files xml costringerebbero ad implementare un software aggiuntivo per la ricerca e l'indicizzazione dei medesimi
- utilizzo in rete, con una soluzione web-based
- rilascio sotto licenza open-source
Lo schema sottostante riassume l'architettura pensata per il software, che si è scelto di chiamare CDAeDit (editor xml del Codice Diplomatico Aretino digitale). Seguono alcune schermate esemplificative della prima versione del software.
Figura 1 – Architettura del software CDAeDit
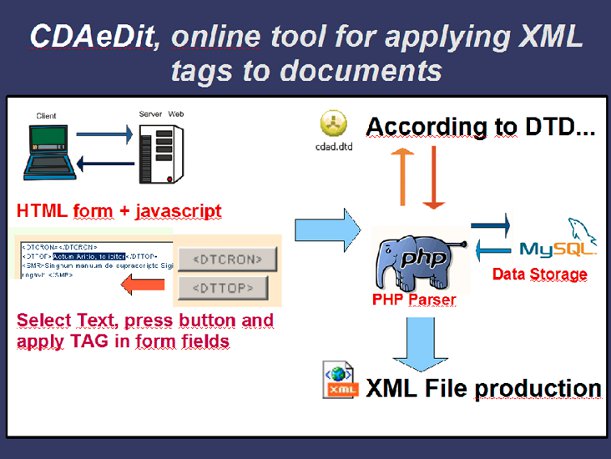
Figura 2 – Accesso all'elenco dei documenti codificati, con indicazione dell'autore e dello stato
Figura 3 – La descrizione del manoscritto e i campi TEI HEADER sono affidati a campi fissi
Figura 4 – La trascrizione del testo si avvale di pulsanti che contengono i marcatori fondamentali per ogni parte del documento. Questo evita errori di annidamento e tag non consentiti.
Figura 5 – Il risultato finale è un file XML che negli obiettivi del progetto deve essere validato DTD TEI
La sperimentazione sul software è ovviamente ancora in corso. In questa prima fase del progetto vi sono ancora obiettivi da raggiungere:
- maggior facilità d'uso
- stabilità e miglioramento dei margini di tolleranza degli errori commessi dall'utente
- miglior collegamento con la TEI P5, per ora limitata ad una sola specifca Document Type Defnition (TEI for manuscripts)
- miglioramento dell'interfaccia grafca, anche grazie al ricorso di AJAX come evoluzione alle funzioni dei pulsanti ora gestite con il semplice JAVASCRIPT. Nei prossimi mesi il software verrà sviluppato e reso produttivo, passando dall'attuale release alpha, dove i meccanismi di base sono appena abbozzati, ad una versione stabile di produzione, rilasciata sotto licenza GNU-GPL (open source)

Progetto Re.Me.DIa. REstauro, MEmorizzazione e DIgitalizzazione Avanzata
© 2009-2013 A.T.I. Remedia e Regione Toscana. Progetto finanziato con fondi POR CREO FESR 2007-2013
asse 1, attività 1.1 linea di intervento D - Contatti